
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 학습하기 #봇 학습 #테스트 방법 #디버깅
- #시그모이드 #광주인공지능학원 #스인개
- RPA #실습 #라이브러리 #RPA라이브러리 #task #Process #Task #Assign #변수
- Class #클래스 #Java #JAVA #자바 #java기초 #java입문 #java #자바 개념 #programming #공부 #개발 공부 #코드 정리 #코딩테스트 #알고리즘
- SQLD #DDL #DML #DCL #TCL #DB #SQLP #DataBase #자격증 # IT #명령어 #SQL #쿼리
- 스마트인재개발원 #광주인공지능학원 #JavaScript #JS #형변환 #자바스크립트 #Web #back-end #front-end
- 스마트인재개발원 #광주인공지능학원 #JavaScript #Web #Java
- 열거형 #enum #JDK5
- Brity #Brity Assistant #ChatBit #챗봇 #자연어 처리 #Brity RPA #삼성SDS #대화분석 #대화설계
- String Class #String #Class
- 메소드 오버로딩 #Method Overloading #오버로딩 #중복정의 #Overloading
- VDI #DRM #디지털 저작권 관리 #가상 데스크톱 인프라 #용어 #IT용어 #개발자 #신입
- 스마트인재개발원 #deep learning #MLP #다층 레이어 퍼셉트론 #퍼셉트론 #선형분류 #다중 선형분류 #AI #머신러닝 #뉴런 #신경망
- #Brity #BrityRPA #FlowControl
- this. #this #this키워드 #객체 자신 참조 #필드호출 #메소드호출
- RPA #실습 #라이브러리 #RPA라이브러리 #task #Process #Task #Script #ExecuteScript
- 대화설계 #시나리오 설계 #Flowchart #플로우차트 작성
- 생성자 #메소드랑 햇갈려 #생성자랑 메소드는 다른거지롱 #객체생성 #new 연산자 #인스턴스화 #인스턴스 생성
- Java #JAVA #자바 #java기초 #java입문 #java #자바 개념 #programming #공부 #개발 공부 #코드 정리 #코딩테스트 #알고리즘
- Class #class #reference
- Brity #BrityRPA #FlowControl
- field #Field #Method #method #필드 #속성 #메소드 #행동 #객체 #Class구성요소
- RPA #실습 #라이브러리 #RPA라이브러리 #task #Process #Task
- 참조(Reference)타입 #클래스
- 연산자 #일치연산자 #기본연산자 #불일치연산자
- 순전파 #역전파 #MLP
- For #Loop #반복문
- 변수의 범위 #Scope #scope #Static #static #지역변수 #전연변수 #global #local
- 스마트인재개발원 #스마트인재캠퍼스 #MLP #이미지분석 #AI #인공지능 #머신러닝 #딥러닝
- Brity Assistant #대화분석 #설계 #ChatBot #변수 #학습 #대화학습 #동의어 #동의어 처리 #단어사전
- Today
- Total
코딩몬
[스마트인재개발원] 머신러닝 기초 & 지도학습(KNN) 본문
지도학습 vs 비지도 학습
지도학습 process
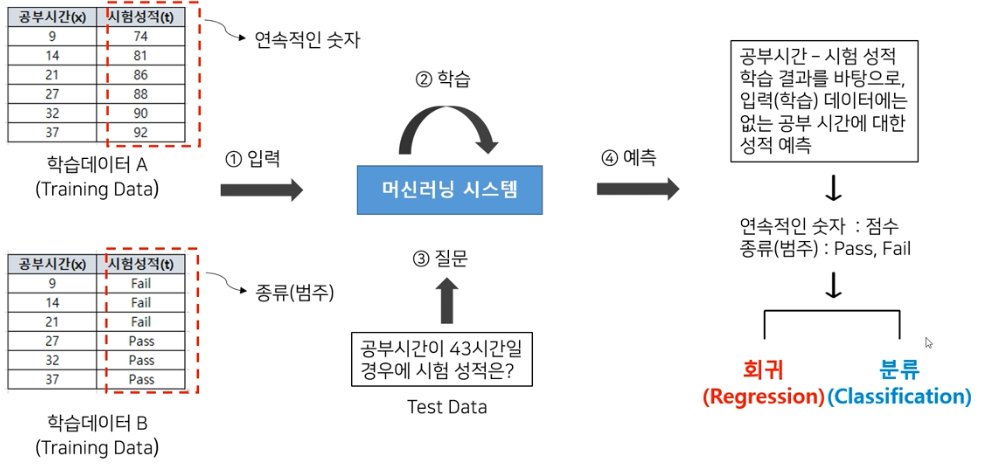
비지도 학습 process
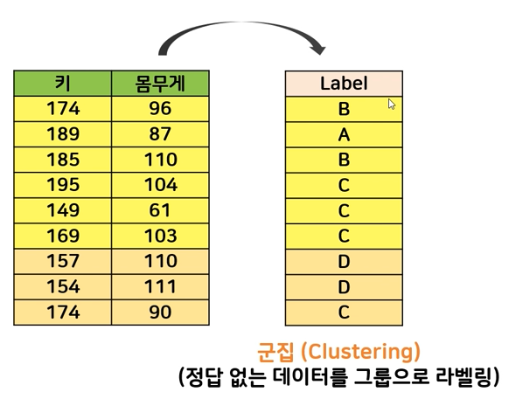
머신러닝(Machine Learning) 학습과정

문제정의
어떤 대상에 대해서 어떤 서비스를 할 것인지, 어떤 모델을 써야 할지, 어떤 학습방법을 선택할 것인지 등프로젝트 방향성에 대한 것을 결정내리는 것
Raw data 수집
날것 그대로의 데이터들을 수집하는 것(ex> 설문조사, 크롤링, 데이터베이스)
Data 전처리
수집한 데이터들을 다듬어 주는 과정, 전체 학습 과정의 70% ~ 80%가량 차지함
K-Nearest Neighbors(KNN) K-최근접 이웃 알고리즘
- 새로운 데이터 포인트와 가장 가까운 훈련 데이터셋의 데이터 포인트를 찾아 예측
- k값에 따라 가까운 이웃의 수가 결정
- 분류와 회귀에 모두 사용 가능


- k 값이 작을수록 모델의 복잡도가 상대적으로 증가(noise 값에 민감) => 과대적합
- k 값이 커질수록 모델의 복잡도가 낮아진다 => 과소적합
- 100개의 데이터를 학습하고 k를 100개로 설정하여 예측하면 빈도가 가장 많은 클래스 레이블로 분류
적은이웃 -> 과대적합 -> 데이터가 살짝만 달라져도 결정경계가 달라저 정확도 하락
많은이웃 -> 과소적합 -> 데이터가 달라져도 결정경계가 변하지 않아서 정확도 상승
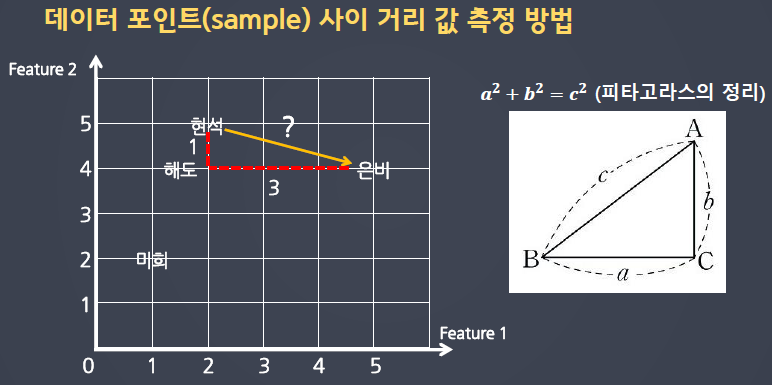

KNN의 주요 매개변수(Hyperparameter)
1. 거리측정 방법
2. 이웃의 수
3. 가중치 함수
<scikit-learn의 경우>
| metric : 유클리디언 거리 방식 n_neighbors : 이웃의 수 weight : 가중치 함수 - uniform : 가중치를 동등하게 설정 - distance : 가중치를 거리에 반비례하도록 설정 |
KNN의 장단점
- 이해하기 매우 쉬운 모델
- 훈련 데이터 세트가 크면(특성, 샘플의 수)예측이 느려진다
- 수백개 이상의 많은 특성을 가진 데이터 세트와 특성 값 대부분이 0인 희소(sparse)한 데이터 세트에는 잘 동작하지 않는다
- 거리를 측정하기 때문에 같은 scale로 정규화 필요
스마트인재개발원
4차산업혁명시대를 선도하는 빅데이터, 인공지능, 사물인터넷 전문 '0원' 취업연계교육기관
www.smhrd.or.kr
'Machine Learning' 카테고리의 다른 글
| [스마트인재개발원] 인공지능 개념 (0) | 2021.06.20 |
|---|
